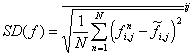 ,
,
Objective Verification of the SAMEX '98 Ensemble Forecasts
Dingchen Hou1, Eugenia Kalnay1,2,3 and Kelvin K. Drogemeier1,2
1
Center for Analysis and Prediction of Storms,2
School of Meteorology,University of Oklahoma
Norman, OK 73019
3
National Centers for Environmental PredictionWashington DC 20233
Last Revision May 28, 1999
Submitted to Monthly Weather Review
_______________
Corresponding author address and current affiliation: Dr. Eugenia Kalnay, Department of Meteorology University of Maryland, College Park, Maryland 20742. ekalnay@atmos.umd.edu
ABSTRACT
During May, 1998, the Center for Analysis and Prediction of Storms (CAPS) at the University of Oklahoma coordinated a multi-institution numerical forecast project known as the Storm and Mesoscale Ensemble Experiment (SAMEX). SAMEX involved the real time operation of four different mesoscale/regional models over the same region and sought, among other things, to compare the value of relatively coarse resolution (30 km) ensemble forecasts against single forecasts made over smaller sub-regions of the Great Plains at both intermediate (10 km) and high (3 km) resolution. Participating in SAMEX were CAPS (running its Advanced Regional Prediction System, or ARPS), the Air Force Weather Agency (AFWA, running MM5), the National Center for Atmospheric Research (NCAR, running MM5), the National Centers for Environmental Prediction (NCEP, running the Eta model and Regional Spectral Model), and the National Severe Storms Laboratory (NSSL, running MM5).
The SAMEX ensembles consisted of a single 36-hour control forecast from the ARPS (at CAPS), MM5 (at NSSL), and the Eta and RSM (at NCEP), all with horizontal resolutions of approximately 30 km. In addition, and most importantly, perturbed runs also were made, resulting in a grand ensemble of 25 members. Despite logistical difficulties, most of the ensemble forecasts were completed for the last 18 days of May 1998, and on 8 days a full set of 25 real time forecasts were completed.
Based on a variety of quantitative analyses, we show that an ensemble of multiple forecast systems appears close to optimal, probably because it represents most realistically the current uncertainties in both models and initial conditions. This result is consistent with the behavior of multi-model global ensembles. In addition, the SAMEX results show that perturbations to model physics parameterizations, as well as the use of boundary condition perturbations consistent with those applied to the interior initial state, are important for regional ensemble forecasting. Efforts are now underway to compare the ensemble forecasts against those made using higher spatial resolution. Additionally, follow-on SAMEX experiments are anticipated in other geographical areas and weather regimes.
1. Introduction
Since the first pioneering experiments conducted by Leith (1974), which showed that a number of numerical forecasts created from slightly different initial conditions can, if appropriately averaged, yield improved skill relative to the individual forecasts themselves, ensemble forecasting has grown into a major area of research and is now a cornerstone of several operational prediction center in the world. The ensemble approach is a computationally tractable method for integrating the probability density function of the atmospheric state forward in time via the prediction of selected individual states, each physically plausible and distinct, drawn from the density function. As shown by Toth and Kalnay (1997), ensemble forecasting is advantageous not because it provides a numerically averaged solution, but because the averaging process serves as a nonlinear filter to selectively smooth unpredictable components of the flow, leaving behind only those features or signals which tend to agree.
Considerable attention has been given to methods for generating the initial conditions of ensemble members, ranging from the simple and efficient (breeding; Toth and Kalnay, 1993) to the complex and computationally expensive (e.g., singular vectors; e.g., Buizza and Palmer, 1993; Buizza, 1995). Such methods aim to introduce perturbations within the subspace of the growing errors, with breeding resulting in perturbations that are related to the leading Lyapunov vectors, and the leading singular vectors representing the fastest growing perturbations. The control initial conditions represent the "best" estimate of the state of the atmosphere, and the added perturbations should be representative of the expected analysis errors.
Following Houtekamer et al (1996), Hammill et al (1999) recently performed simulation experiments indicating that the most realistic ensemble can be obtained from an ensemble of data assimilations, where the observations are perturbed with random errors. In the perturbed observations method (PO) the random errors project onto the subspace of leading Lyapunov vectors, so that the results are similar (but somewhat better) than breeding, and the perturbation growth is much smaller than that of singular vectors. More recently, perturbations to the models that account for uncertainties due to the use of imperfect models have also been introduced in ensemble forecasting by varying model physics parameterizations (e.g., Stensrud et al., 1998, Houtekamer and Mitchell, 1998, Miller et al, 1999). Perturbations in the physics may be much more important for mesoscale short range ensemble forecasting than in global models.
Practical experience serves as a useful guide in assessing appropriate ensemble strategies and, perhaps not surprisingly, evidence from the large scale shows that ensemble averaging applied to forecasts from different models, each of which is started from the "best" initial condition possible, yields results that are significantly better than the individual forecasts (e.g., Wobus and Kalnay, 1995). Although the multi-model approach does not fit squarely within the classic ensemble framework of perturbations to initial conditions, it is sensible that the "best possible" forecasts produced by completely different systems would, when averaged, yield greater skill than even the best individual forecast given the nature of the nonlinear filtering process.
Ensemble forecasting has long been applied to the large-scale atmosphere and became operational for the global forecasting systems at NCEP and the ECMWF in December 1992 (Toth and Kalnay, 1993, Molteni and Palmer, 1993). It is now widely used by forecasters to assess the reliability of the day-to-day forecasts (e.g., Toth et al, 1997). More recently, ensemble strategies have been used in limited-area models (e.g., at 60 to 80 km resolution). The potential advantages of this so-called "short range ensemble forecasting" (SREF; Brooks et al., 1995; Du et al., 1997) were first discussed during a workshop held at NCEP in 1994 (Brooks et al, 1995), where it was concluded that SREF should be especially useful for precipitation forecasting. As a result, experimental ensemble forecasting systems were developed using the Eta and RSM models at NCEP (Tracton et al, 1999, Du and Tracton, 1999) and the MM5 at the National Severe Storm Laboratory (NSSL) (Stensrud et al, 1999). SREF has proven notably effective, particularly with regard to ensembles among multiple models (e.g., Hammill and Colucci, 1997).
As numerical forecast systems and observational platforms (e.g., the WSR-88D Doppler radar) continue to focus on smaller scales of the atmosphere, and as our understanding of physical processes continues to improve, greater emphasis will to be placed on the prediction of intense local weather using non-hydrostatic models at resolutions of 1 to 10 km. Indeed, the Weather Research and Forecasting (WRF) model, being developed as a dual-purpose research and operational system by the national community (e.g., Dudhia et al., 1998), is targeted specifically at such resolutions.
At this point in time, however, the specific data requirements, analysis and assimilation strategies, and spatial resolution and physics parameterizations needed to accurately predict the initiation, evolution, and decay of intense meso-beta and meso-gamma weather systems are not well established. Thus, as the scientific and operational communities explore strategies for dealing with the detailed short-range prediction of intense local weather, a question of fundamental importance must be addressed: what is the relative value of an ensemble of coarse-resolution (20 to 30 km grid spacing) forecasts compared to a much smaller number of shorter-duration forecasts run at considerably higher resolution (1 to 3 km) and at similar computational cost? The answer to this and related questions has far-reaching implications for the manner in which the US invests in future scientific research and technology acquisition, and efforts must be directed toward providing an answer so as to maximize available resources.
During the past decade, a number of groups in the US and abroad have begun to experiment with mesoscale forecast models that seek to resolve explicitly, using high spatial resolution grids and observational data, the most important processes associated with intense convective and winter precipitation systems. Operationally, the Eta model (e.g., Black 1994, Mesinger, 1996) and the Rapid Update Cycle (RUC, Benjamin et al, 1996) have recently been implemented at mesoscale resolution at the National Centers for Environmental Prediction (NCEP) for short-range predictions over North America. Several state-of-the-art non-hydrostatic models appropriate for storm-scale prediction have been developed as well, and some are also used for regional forecasting.
For example, the Advanced Research and Prediction System (ARPS), developed by the Center for Analysis and Prediction of Storms (CAPS) at the University of Oklahoma, has been run on a daily basis for over 2 years with an emphasis on assimilating Doppler radar, satellite, and commercial aircraft observations to predict multi-season storms at spatial resolutions down to 3 km (Droegemeier, 1997; Carpenter et al., 1997, 1998, 1999). The Mesoscale Model version 5 (MM5), developed jointly by the National Center for Atmospheric Research (NCAR) and the Pennsylvania State University (Dudhia 1993, Grell et al, 1994), also has been used for routine regional short range predictions (e.g., Stensrud, 1999). The NCEP Regional Spectral Model (RSM) is closely related to the NCEP global model and has been used for short-range forecast and climate applications (Juang et al, 1997).
In an attempt to build upon these many modeling activities, several groups joined forces in a national-regional numerical weather prediction experiment during the spring, 1998 convective season. Known as SAMEX '98 (Storm and Mesoscale Ensemble Experiment, spring 1998; Droegemeier, 1997), this effort involved a real time comparison of some 20 to 25 ensemble forecasts, run at approximately 30 km resolution using 4 different models, against a much smaller number of forecasts run at both intermediate (10 km) and high (2-3 km) resolution over sub-sets of the ensemble domain.
Coordinated by the Center for Analysis and Prediction of Storms (CAPS) at the University of Oklahoma, SAMEX involved the National Severe Storms Laboratory (NSSL), Air Force Weather Agency (AFWA), National Center for Atmospheric Research (NCAR), and the National Centers for Environmental Prediction (NCEP). Additionally, a number of other groups participated in the real time forecast evaluation process, including several National Weather Service Forecast Offices (NWSFOs), the Storm Prediction Center (SPC), Tinker Air Force Base, and the Aviation Weather Center (AWC).
SAMEX was novel in several ways. First, it provided for a direct comparison of several techniques for generating mesoscale ensemble initial conditions (bred perturbations, scaled-lagged average forecasting, Monte Carlo, and multiple physics options). Second, the ensembles from each forecast system were themselves combined to create a multi-model "grand ensemble." Third, it provided a framework for quantifying the relative value and computational expense of low-resolution probabilistic and higher resolution deterministic forecasts and developing techniques for verification and comparison. Fourth, it was conducted as a multi-institution effort that included NCEP and leveraged several ongoing activities in experimental real time NWP. And finally, it exposed operational forecasters, in real time, to technologies that are scheduled to become operational within the next several years. SAMEX involved no comparisons of or competition among models; all participating forecast systems demonstrated similar capabilities, on average, with each excelling in one or more aspects.
Despite its rapid organization and relatively short duration, SAMEX '98 resulted in an unprecedented data set that is providing opportunity for a large number of model and ensemble intercomparisons. Plans now underway to complete higher resolution runs for smaller areas embedded within the larger domain of SAMEX '98 should further enhance the utility of this data set. Future coordinated SAMEX experiments in other regions and seasons are planned as part of the US Weather Research Program (USWRP), and should further contribute to our understanding of the characteristics of different models and their application.
The purpose of this paper is to present verifications of the ensemble forecasting system utilized during SAMEX '98, and to explore the advantages and disadvantages of different perturbation methods as well as the use of different model and data assimilation systems. There is no intent to rank a given model's performance: all models used during SAMEX '98 are state-of-the-art and demonstrated similar capability, each excelling in one or more measures. On the other hand, the identification of specific model problems should provide a basis for improvement.
The logistics of SAMEX '98 and the method by which the ensemble initial conditions were created are described in Section 2. An analysis of ensemble spread is presented in Section 3, and in Section 4 we verify the bias and standard deviation of the individual and ensemble mean forecasts. Rank distribution diagrams are presented in Section 5, and Section 6 includes extensive probabilistic verifications. A summary and discussion are given in Section 7.
2. SAMEX '98 Ensemble Forecast System and Data Set
As indicated in the introduction, the first Storm and Meso-scale Ensemble Experiment (SAMEX '98) was conducted during May over the continental US and central/southern Great Plains. Performed without any new funding, SAMEX '98 was a proof-of-concept effort that sought to:
Three centers participated in this project by running four different numerical models: the CAPS Advanced Regional Prediction System (ARPS), the NCEP Eta model and the Regional Spectral Model (RSM), and the NCAR/Penn State meso-scale model version 5 (MM5) used by NSSL. (Note that NCAR and the Air Force Weather Agency also participated by running the MM5 system, though not in an ensemble mode.) Each model was used to create a control run, along with a number of runs for which the initial conditions (and, in some cases, boundary conditions) were perturbed. The methods used to generate the perturbations in each system are given below (see Table 1).
Table 1. Summary of the SAMEX '98 ensemble forecast system
Name Institution Model Number of members Method of Member Generation
CAPS CAPS ARPS 5 Scaled Lagged Average Forecasting
NCP1 NCEP Eta 5 Bred Perturbations from global system
NCP2 NCEP RSM 5 Bred Perturbations from global system
NSSL NSSL MM5 10 Perturbations in IC & Change in Physics
FULL Multi-Model 25 Perturbations in IC, BC & Physics
CNTL Multi-Model 4 The four models control runs
All forecasts in the ensembles were started at 00Z and integrated for 36 hr. The output from the forecasts, including the initial conditions, were interpolated to a common grid with horizontal spacing of 30 km for the purposes of display and verification. The common domain is shown in Fig. 1 and includes the central and eastern parts of the United States. Numerous forecast products including mean and spread charts, spaghetti diagrams, and conditional probability plots were available in real time on the web. Also available were all of the individual forecasts composing the ensemble.
Fig. 1 The common domain used for forecast display and verification.Despite the technical difficulties associated with an experiment of this magnitude, SAMEX '98 generated an excellent data set for the period 14-31 May 1998, with only some members missing on particular days (Table 2). A complete ensemble data set is available for 8 days, and on 18 days the majority of the forecasts were completed. It will be shown that the average of the complete 8 cases is reasonably representative of the entire data set. The initial conditions from the Eta operational model interpolated to the SAMEX' 98 common domain were used as the verifying analysis. The time evolution of quantities such as ensemble spread and error are shown at 3-hour intervals, while for other verification parameters only the 12-, 24- and 36-hour forecasts are presented.
Table 2: Dates in May 1998 for which the ensemble forecasts are available. The eight dates with complete ensembles are indicated in bold.
CAPS NCP1 NCP2 NSSL
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
CT +12 +24 -12 -24 CT P1 P2 N1 N2 CT P1 P2 N1 N2 CT P1 P2 P3 P4 P5 P6 P7 P8 P9
14 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y N N N N N N N N N N
15 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
16 Y Y Y Y Y N N N N N N N N N N Y Y Y Y Y N N N N N
17 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
18 Y Y N Y N Y Y Y Y Y Y Y Y Y Y N N N N N N N N N N
19 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y N N N N N N N N N N
20 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
21 Y Y N Y N Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
22 N N N N N Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y N N N N N
23 Y Y Y Y Y Y Y Y Y Y N Y Y Y Y Y Y Y Y Y Y Y Y Y Y
24 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
25 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
26 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
27 Y Y Y Y Y N N N N N Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
28 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y N
29 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
30 Y Y Y N Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
31 Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
3. Ensemble spread and evolution with time
In an ideal forecast ensemble, the verification should appear as a plausible member of the ensemble (Toth and Kalnay, 1993). In order to satisfy this condition, a desirable feature of an ensemble system is that the perturbations introduced either in the IC or during the course of the forecast (as in the case of changes in the model physics) should grow at a rate comparable to the observed growth of forecast errors. It is easy to show that the average squared distance between two ensemble members is equal to twice the average squared distance between an ensemble member and the ensemble mean. Therefore, a convenient measure of the amplitude of the perturbations is the spread (SP) of the ensemble forecast members about the ensemble mean, defined as the RMS difference from the ensemble mean of all of the ensemble members, averaged over the entire domain, i.e.,
,
\* MERGEFORMAT ()1
where f is a model predicted variable, with subscripts i and j denoting the grid indices and the superscript n the ensemble member index, and N is the number of members in the ensemble. The overbar represents the domain average and a tilde the ensemble mean, i.e.,
![]() ,
,
\* MERGEFORMAT ()2
is the ensemble average, and
![]() ,
,
\* MERGEFORMAT ()3
is the domain average.
We found (not shown) that, for all forecast quantities, the results corresponding to the 8 complete cases are very similar to those obtain for the entire 18-day data set (Table 2). In light of this fact, and because some verification measures require complete data sets, only the results for the complete 8-case average will be discussed in the remainder of the paper.
Fig. 2 shows the averaged spread for mean sea level pressure (MSLP), height at 250hPa (HGT250), 500hPa (HGT500) and 850hPa (HGT850). These "mass" or "height" variables show similar features, of which the most distinctive is a large peak at 3-hr, which does not appear in the temperature, thickness or moisture variables (cf. Fig. 3). This suggests that the large spread at 3 hr is associated with a geostrophic adjustment process with the presence of external gravity waves, affecting the MSLP, and through hydrostatic balance, the geopotential heights at upper levels. Since it does not appear in individual ensembles spread, it must be related to an initial imbalance shared by all the members of at least one ensemble system. The spread computed without the NSSL forecasts (not shown) does not have a peak at 3-hr, indicating that the initial imbalance is associated with the NSSL ensemble.Another interesting observation is that the ensemble spread of the mass variables grows at a similar fast rate for NCP1, NCP2 and CAPS, indicating dynamical growth of the initial perturbations (Fig. 2). After the initial decay due to lack of balance, the NSSL ensemble geopotential height spread grows but at a lower rate than the other systems, presumably because the boundary conditions in the outer domain are the same for all of its members and because of the use of random perturbations.
The most notable characteristic in Fig. 2 and follow-on, however, is that the FULL ensemble spread is much larger than those of the individual ensembles throughout the integration. Furthermore, it shows steady growth after of the initial oscillations during the first 12 hours and its growth rate is significantly larger than the average growth rate of the individual ensembles spread. This suggests that the use of different analyses and different models leads to an effective ensemble with stronger spread growth than attained by any individual system.
The spread of several variables associated with temperature and moisture, i.e. temperatures at 850hPa (TMP850), 2m temperature (TEMP2M), dew point (DEWP2M), and 3hr accumulated precipitation (ACCPPT) is shown in Fig. 3. The spread of these variables evolves quite differently from the height fields spread of Fig. 2. The NSSL ensemble, which includes different combinations of physical parameterizations for the boundary layer and for the cumulus convection, has much larger growth in spread than the other models. In the surface temperature and dew point spread, the NSSL ensemble has a very strong diurnal signal, with the maximum spread in the dew point at 21Z (about 15hr local time), and in the temperature at 24Z (about 18hr local time). The CAPS ensemble, on the other hand, has a large initial spread, but no further growth, an undesirable feature. It is possible that this is due to the fact that during SAMEX '98 the initial conditions for the soil properties where the same for all the runs in the ARPS ensembles. As with other variables, the spread of the 3-hour accumulated precipitation (ACCPPT) for the FULL ensemble is significantly greater than for the individual ensembles. The Eta ensemble (NCP1) precipitation spread is surprisingly small and devoid of growth. This is an undesirable characteristic for this ensemble, suggesting that the precipitation is not sensitive to dynamical perturbations, and may be associated with the way the bred perturbations are interpolated to the Eta initial conditions. The CAPS ensemble has a much stronger diurnal cycle in precipitation spread than the other models, which may or may not be realistic. D. Stensrud (pers. communication, 1999) has suggested that the relatively low spread of the Eta model temperature and precipitation may be due to the fact that the Betts-Miller-Janjic convective adjustment scheme does not change significantly the low level temperature and moisture, due to the lack of downdraft cooling. The ARPS model (CAPS) used a Kuo parameterization in this experiment, which also changes minimally the soundings at low levels.
For the thermal variables, the spread of the FULL ensemble is also significantly greater than those of individual ensembles (Fig. 3) and shows a reasonable increase with time for 850hPa temperature and 500-1000hPa thickness. As indicated before, the same is true for the spread of precipitation.
Fig. 2 Time series of the ensemble spread for mean sea level pressure (MSLP), 250hPa heights (HGT250), 500 hPa heights (HGT500), and 850hPa heights (HGT850), averaged over the 8 cases with complete data sets.
Fig. 3: Same as in Fig. 2 but for temperature at 850 hPa (TEMP850), the 2m surface air and dew point temperature (TEMP2M and DEWP2M) and 3hr accumulated precipitation (ACCPPT).
From the results in this section, it can be concluded that the FULL ensemble is significantly superior to the individual ensembles in that it provides a better chance to encompassing the truth with greater growth in the spread. This strong advantage is due to the use of different models and different initial conditions, which reflect better the current uncertainties in initial conditions and model formulation than a "synthetic" ensemble system, no matter how carefully it is designed. This efficiency of a multi-model system, already noted for global models (e.g., Wobus and Kalnay, 1995), provides a benchmark that improvements in the perturbation generation schemes for single models may be able to achieve in the future.
4. Ensemble forecast errors
In this section we perform forecast verifications and investigate the improvement in the forecast due to the use of ensemble average compared with individual members, and the impact of using FULL ensembles compared with individual ensembles. Because our verification involves 2-D atmospheric fields, we start with a widely used measure of horizontal average error, namely, mean square error (MSE). If f is a single forecast variable and v the corresponding verifying analysis, MSE is defined (Wilks, 1995) as
![]()
\* MERGEFORMAT ()4
where the overbar indicates as before domain average. The mean squared error can be separated into the square of the domain bias BIAS2 and the error variance VAR (square of the standard deviation of the error SDE). The variance, in turn can be separated into systematic and random components:
![]()
![]() , (5a)
, (5a)
or
![]() (5b)
(5b)
where
![]() (6a)
(6a)
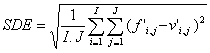 (6b)
(6b)
![]() (6c)
(6c)
![]() (6d)
(6d)
Here, ![]() ,
, ![]() , SD is the standard deviation of the forecast or the verification, and r(f,v) is the pattern correlation (CORR) between the forecast and verification fields. The MNBIAS (bias of the mean) and the SDBIAS (bias of the standard deviation) in eq. (5b) measure the systematic components of the domain-averaged forecast error, and can be corrected a posteriori by subtracting the bias and by inflating or deflating the standard deviation of the forecast. The last term in (5b) is the dispersion error (DISP), proportional to one minus the pattern correlation (CORR) between the forecast and the verification. Because it cannot be "calibrated out" it can be considered the most important measure of the forecast skill. As pointed out by Takacs (1985), phase errors, rather than amplitude errors affect the dispersion error.
, SD is the standard deviation of the forecast or the verification, and r(f,v) is the pattern correlation (CORR) between the forecast and verification fields. The MNBIAS (bias of the mean) and the SDBIAS (bias of the standard deviation) in eq. (5b) measure the systematic components of the domain-averaged forecast error, and can be corrected a posteriori by subtracting the bias and by inflating or deflating the standard deviation of the forecast. The last term in (5b) is the dispersion error (DISP), proportional to one minus the pattern correlation (CORR) between the forecast and the verification. Because it cannot be "calibrated out" it can be considered the most important measure of the forecast skill. As pointed out by Takacs (1985), phase errors, rather than amplitude errors affect the dispersion error.
As indicated before, the Eta model initial conditions (0 hr forecast) were used as verifying analysis. The MNBIAS, SDBIAS, DISP and CORR were calculated for each case and averaged for the 8 complete cases. As with the spread, these results were representative of the average obtained when using all 18 almost complete cases. The time series of the MNBIAS, SDBIAS, DISP and CORR of the individual ensemble averages as well as the FULL and CONTROL ensemble averages for HGT500 and TMP850 are shown in Fig. 4 and Fig. 5, respectively. The plot also includes the 0hr forecast, i.e. the initial conditions, although at that time they are not representative of forecast errors but of the choice of initial conditions and verification. The CAPS and NSSL have much smaller initial SDE compared with the NCEP ensembles. This is because the former systems used the operational Eta model output as the basis of initial conditions, the same as the verifying analysis, whereas the control NCEP forecasts where obtained from the global system.
Fig. 4 Time series of average error statistics for 500 hPa for individual ensembles and the FULL and CONTROL ensembles. a) Mean bias error MNBIAS, b) Bias of the standard deviation, c) dispersion (DISP) error, and d) forecast/analysis correlations. The average score of the individual ensemble members are also indicated with different symbols.
Fig. 5: Same as in Fig.4 except for TMP850.
Significant differences between the mass variables and the thermal variables are noticed in the MNBIAS. Fig. 4a shows that MNBIAS of HGT500 has a strong diurnal cycle, in all the ensembles. Because the minima are at 00h and 24h (about 18 hr local time), and maxima at 12 h and 36h (about 6 hr local time), respectively, the diurnal cycle indicates not enough elevation of the 500hPa surface during the day time. In contrast, the MNBIAS in TEMP850 (Fig. 5a), especially those of NSSL and CAPS, displayed a clear tendency of cooling with time. The two NCEP ensemble averages show little tendency of cooling MNBIAS (0.5K or less up to 36h). The CAPS ensemble has a stronger cooling tendency (about 0.8K over 36hrs) and NSSL cools the most (about 1.4K in 36 hrs). The NSSL ensemble average cools considerably more than the control forecast (1.4K vs. 0.8K), suggesting that the changes in the model physics are the origin of additional cooling bias. The FULL and CONTROL ensembles show some cancellation of errors in the bias.
The bias in the SD (SDBIAS) in Figs. 4b and 5b is a relatively small error term compared to the overall MNBIAS or to the dispersion component of the standard deviation of the error. It indicates that all the models are fairly good in representing the atmospheric variability during this period, although the NSSL overestimates the variability in height, and NCEP1 tends to underestimate it.
As indicated above, the most useful measure of the actual forecast skill is the dispersion component of the error (Figs 4c and 5c). First we note that among the individual systems, both NCEP models have smaller standard deviation of height errors, and the Eta model has the best temperature errors, compared to the non-operational CAPS and NSSL forecasts. The 8-case average for each of the individual ensemble members is also indicated in Figs. 4 and 5 with symbols. It can be observed that (with the exception of the heights in the NSSL ensemble), the dispersion error for each ensemble average is lower than the individual members dispersion error (including the control forecast). This is an important result indicating that nonlinear ensemble filtering of errors occurs very early in these short-range ensemble forecasts.
The most remarkable result in Figs. 4c and 5c, however, is that the FULL ensemble average has DISP errors substantially smaller than all of the individual ensemble averages (and the CONTROL ensemble is a close second). This is true for HGT500 and for all other variables (not shown), but is especially clear with the temperature forecast errors at 850hPa. Fig. 5c shows that the DISP error of the FULL ensemble is less than the NCP1 (Eta model), the smallest among the individual ensembles, by about 0.3C. The time correlation plots (Figs. 4d and 5d) also show that the multiple model ensembles are far superior to any individual ensemble, having an advantage of 24 hours in forecast skill using this measure. The CONTROL ensemble does also quite well, at a level almost comparable to the FULL ensemble.
The fact that (with the exception of the NSSL height) the ensemble average errors for the individual systems are smaller than the control error is shown in more detail for the CAPS ensemble. Fig. 6 shows the SDE errors associated with the control run, the error averaged over the 4 perturbation members, and the error of the ensemble average. Since the control is the best estimate of the initial conditions, it is not surprising that the four perturbed runs have individually larger rms errors than the control run. Nevertheless, the ensemble average including these perturbations provides a significantly better forecast than the control. This is especially clear with the temperature (Fig. 6, lower panel), indicating that even at this short range, there is a beneficial effect from nonlinear ensemble filtering of the errors. We also note that in the CAPS ensemble, the control was subjected to a mesoscale analysis using the ARPS Data Assimilation System (ADAS, Brewster et al, 1996), which increases its initial difference with the operational Eta initial conditions, used for verification.
Fig. 6 Time series of SD of errors (SDE) of HGT500 (upper panel) and TMP850 (lower panel), for CAPS ensemble, averaged over the 8 cases of complete data sets.
We looked at histograms of the number of forecasts for which an individual ensemble member is the "best", defined as the forecast that has the smallest BIAS or SDE (not shown). These diagrams showed that despite the fact that the control runs had the smallest SDE, they were not the most frequent best ensemble member.
5. Rank Distribution
As demonstrated by Zhu et. al (1996), the verification of the rank distribution of ensemble system suggested by Talagrand (pers. comm., 1996) and independently by Anderson (1996) is a useful measure of the realism of an ensemble (but not of its skill, see next section). This method checks whether the verifying analysis appears as a plausible ensemble member. At each grid point the forecast values from each of the ensemble members are ordered from smallest to largest. For our FULL ensemble, with 25 members, this creates 26 intervals or bins. The value of the verifying analysis at this point then falls into one of the 26 categories or bins. If the analysis is less than the smallest value of the member forecasts, it falls in category 1, and if greater than the largest of the forecast values it falls in category 26. The same is done for all the grid points and all of the 8 complete cases, and the average frequencies at which the verifying analysis falls into each of the 26 categories are determined. Figs. 7 and 8 show the Talagrand diagrams for HGT500 and TMP850, respectively, i.e., the histograms of the frequencies as a function of the category index.
Fig. 7. Relative frequencies at which the verifying analysis falls in each of the 26 categories, defined by the 25 ordered ensemble members at each grid points, for the FULL ensemble HGT500 forecast. a) 12hr forecasts; b) 24hr forecasts; c) 36 hr forecasts.
Fig. 8 Same as in Fig 7 except for TEMP850.
In an ideal ensemble all the perturbations in initial conditions, boundary conditions and changes in model physics should represent equally likely scenarios, and if the verifying analysis behaves like an ensemble member, the Talagrand diagram should be flat. For the 500 hPa heights, the distribution is indeed quite flat, although the two extreme categories are somewhat higher than their adjacent categories. The 36h forecast is particularly good in this respect, even though the accuracy of the forecast decreases with time. There is a shift of frequencies of the verifying analysis from the lower categories to higher categories between 12h and 24 hours, consistent with the positive MNBIAS of the FULL ensemble average at 12 hr, and the negative MNBIAS at 24hr, as shown in Fig. 4.
The Talagrand distribution of TEMP850 shows a systematic bias towards the higher categories, increasing with the lead time. This could be expected from the systematic cold bias of the temperature forecasts from the FULL ensemble shown in Fig. 5. If the MNBIAS had been corrected, this plot would have been also fairly flat (not shown).
The Talagrand distributions of HGT500 and TEMP850 from individual ensemble systems (not shown) are much less flat than the FULL ensemble distributions, and they show larger proportions of the verifications falling outside the ensemble (in the extreme categories). The sum of the frequencies of the two extreme categories represents the relative frequency of cases in which the ensemble failed to encompass the truth and is therefore referred to as "missing rate". However, with different numbers of members in each ensemble, the missing rate cannot be directly compared because an ensemble with a larger number of members would have a better chance to encompass the truth. Following Zhu et al (1996) the missing rate is adjusted for ensemble size by subtracting the expected missing rate if the verification is evenly distributed among all of the categories. The expected missing rate for a perfect ensemble of 25 members, is 2/(25+1) or about 7.7%. For the individual ensembles, this correction is 33% (NCP1, NCP2, CAPS) or 18% (NSSL). The CNTL ensemble has only 4 members, so its adjustment is 40%. The "adjusted missing rates" for all of the 6 ensembles are shown in Fig. 9. It is clear that for all of the variables and all forecast leads, the FULL ensemble has an adjusted missing rate smaller than any of the individual ensembles and much smaller than their average. In fact, the adjusted missing rate is less than 10% in most cases. This indicates that the members of the FULL ensemble are much more representative of all the possible scenarios, compared with the individual ensembles. The adjusted missing rate associated with the CNTL ensemble is even lower, and mostly negative for the sea level pressure. Negative adjusted missing rates indicate that the members of the ensemble have an excessive spread. Except for this, the CNTL ensemble has excellent scores for adjusted missing rates, suggesting that the improvement of the forecast by using the FULL ensemble average is due, to a large extent, to the use of multiple models. Further improvements can be expected with better methods of generation of perturbation members. Comparing the individual ensembles, it is apparent that the two operational models do fairly well in the MSLP and 500hPa heights, but as we saw before, they don't have enough spread in the temperature. The NSSL system, the only one with perturbations in the physics, does best for the temperatures, but worst at 500 hPa. The CAPS system does worst in MSLP.
Fig. 9: Frequencies at which the ensemble does not encompass the verifying analysis, adjusted according to the size of the ensembles (see the text for detail).
6. Probability Verification Measures
One of the most important applications of the ensemble forecasts is their use for generation of probabilistic forecasts. The Rank Distribution (Talagrand) diagrams of the previous section show the extent to which the ensembles encompass the truth and the bias in the probability distributions. However, they cannot measure the usefulness of the forecast: an ensemble created from a random climatological distribution of states of the atmosphere would result in a perfectly flat Talagrand diagram for a sufficient number of forecasts, but would have no useful information beyond that contained in climatology. In this section, we evaluate the performance of a simple probabilistic forecast of HGT500 and TEMP850 based on the FULL ensemble. Because of their insufficient number of members, the individual ensembles and CNTL ensemble are not included in this evaluation.
The probabilistic forecasts were created by determining the percentage of the ensemble members that fall into any of 10 climatologically equally likely bins. These bins were determined by Zhu et al (1996) using the climatological data base from the NCEP/NCAR Reanalysis (Kalnay et al, 1996), and were kindly made available to us for this study. The original climatological bins were computed on the 2.5o lat. x 2.5o long. global grid of the reanalysis, and a distance-weighed interpolation scheme was used to generate the same bins for the SAMEX '98 grid. Fig 10 shows the climatological bin limits for HGT500 and TEMP850 for a point near the center of the domain.
Fig. 10: a) Bins of equal probabilistic distribution of the climatological 500 hPa heights during May at a point in the center of the SAMEX domain. b) Same as a) but for 850 hPa temperatures.A forecast probability yi for each of the 10 bins is given by the relative number of forecast members falling within that bin, and since there are 25 independent forecasts it can only take one of the following 26 values: 0/25, 1/25,…24/25, 25/25, or 0%, 4%,…, 96%, 100%. On the other hand, the observed probability of the event, o, can only be o1=1 (when the observation does falls within the bin) or o2=0 otherwise. Similar to the mean square error in Eq.(4), the Brier Score (BS) is essentially the mean-squared error of the probability forecasts:
![]() (8)
(8)
where the summation takes place over all n forecast/observation pairs available for all grid points and all 8 cases. Murphy (1973) showed that the Brier Score can be separated into three components:
![]() (9)
(9)
where ni is the number of times a forecast yi is used in the collection of forecast/verification pairs, ![]() is the observed average frequency of the verification falling into each bin, and
is the observed average frequency of the verification falling into each bin, and ![]() is the conditional frequency of the verification falling into a bin when a forecast yi has been issued.
is the conditional frequency of the verification falling into a bin when a forecast yi has been issued.
The three terms on the right hand side of (9) are known as reliability, resolution and uncertainty respectively. The uncertainty ![]() is independent of the forecast method. Table 3 shows the reliability, resolution and total Brier Score for each of the ensemble systems for the 8 complete days. It shows that the FULL (and to a lesser degree the CONTROL) ensembles had excellent reliability for both the heights and the temperatures. NSSL had relatively poor reliability for the heights, but it was the best individual system for the temperatures. In general, the individual systems had comparable resolution, which decayed with forecast length. CAPS was the best individual system at 24 hr.
is independent of the forecast method. Table 3 shows the reliability, resolution and total Brier Score for each of the ensemble systems for the 8 complete days. It shows that the FULL (and to a lesser degree the CONTROL) ensembles had excellent reliability for both the heights and the temperatures. NSSL had relatively poor reliability for the heights, but it was the best individual system for the temperatures. In general, the individual systems had comparable resolution, which decayed with forecast length. CAPS was the best individual system at 24 hr.
Table 3. Comparison of the Brier Score and its components (reliability and resolution) calculated from the 8 complete cases. The third component of the Brier Score (uncertainty, not shown) is equal to 0.090 and is the same for all forecasts.
HGT500 TEMP850
BS REL. RES. . BS. REL. RES.
t=12h 0.061 0.009 -0.038 0.059 0.005 -0.036
CAPS t=24h 0.053 0.005 -0.042 0.065 0.009 -0.034
t=36h 0.075 0.011 -0.026 0.094 0.018 -0.014
t=12h 0.046 0.003 -0.047 0.078 0.015 -0.027
NCP1 t=24h 0.063 0.007 -0.035 0.068 0.010 -0.033
t=36h 0.068 0.008 -0.030 0.086 0.015 -0.019
t=12h 0.053 0.004 -0.042 0.076 0.012 -0.026
NCP2 t=24h 0.071 0.009 -0.028 0.071 0.011 -0.030
t=36h 0.080 0.011 -0.021 0.089 0.015 -0.016
t=12h 0.071 0.014 -0.033 0.059 0.004 -0.035
NSSL t=24h 0.065 0.011 -0.035 0.051 0.002 -0.041
t=36h 0.074 0.012 -0.028 0.076 0.005 -0.019
t=12h 0.043 0.001 -0.048 0.055 0.003 -0.038
CNTL t=24h 0.049 0.002 -0.043 0.051 0.003 -0.042
t=36h 0.058 0.003 -0.035 0.073 0.006 -0.023
t=12h 0.045 0.001 -0.045 0.052 0.001 -0.039
FULL t=24h 0.048 0.000 -0.042 0.048 0.001 -0.042
t=36h 0.056 0.001 -0.035 0.069 0.001 -0.024
The terms in (9) can also be interpreted geometrically with a reliability diagram (Wilks, 1995) in which the observed frequency (subsample relative frequency) ![]() is plotted as a function of yi, the forecast probability. Reliability diagrams for HGT500 and TEMP850 are shown in Figs.11a and b. The insert in each diagram shows the size of the corresponding subsample (histogram), ni, as a function of yi. Because the ni values are calculated from all the 10 bins and the 8 complete cases, the histogram shows that most of the forecast probabilities are zero or close to zero. However, there is also a noticeable maximum in the histogram for forecast probability 1, indicating that the forecasts show significant resolution. Since the reliability in (9) is the sum of the squared difference between yi and
is plotted as a function of yi, the forecast probability. Reliability diagrams for HGT500 and TEMP850 are shown in Figs.11a and b. The insert in each diagram shows the size of the corresponding subsample (histogram), ni, as a function of yi. Because the ni values are calculated from all the 10 bins and the 8 complete cases, the histogram shows that most of the forecast probabilities are zero or close to zero. However, there is also a noticeable maximum in the histogram for forecast probability 1, indicating that the forecasts show significant resolution. Since the reliability in (9) is the sum of the squared difference between yi and ![]() , the diagonal line in Figs. 11 represents perfect reliability. For both variables and all lead times, the curves showing
, the diagonal line in Figs. 11 represents perfect reliability. For both variables and all lead times, the curves showing ![]() as a function of yi are quite close to the diagonal, indicating that the forecasts are quite reliable. The TEMP850 24h forecasts, show overforecasting of medium probability and underforecasting of higher probability (and similarly for the 36hr forecast, not shown). However, most of the forecasts are excellent for low probability (30% or less) and highest probability (92% or over). Considering the fact that the results have not been calibrated, and that the sample is concentrated in these two ranges, the FULL ensemble is very successful. Note also that we have plotted the "no skill" line for which the resolution is equal to the reliability (Wilks, 1955, p265). Since all the points in Fig. 11 are above the no skill line, all the subsamples of forecasts contribute positively to the overall skill.
as a function of yi are quite close to the diagonal, indicating that the forecasts are quite reliable. The TEMP850 24h forecasts, show overforecasting of medium probability and underforecasting of higher probability (and similarly for the 36hr forecast, not shown). However, most of the forecasts are excellent for low probability (30% or less) and highest probability (92% or over). Considering the fact that the results have not been calibrated, and that the sample is concentrated in these two ranges, the FULL ensemble is very successful. Note also that we have plotted the "no skill" line for which the resolution is equal to the reliability (Wilks, 1955, p265). Since all the points in Fig. 11 are above the no skill line, all the subsamples of forecasts contribute positively to the overall skill.
Fig.11: 24 hour forecast reliability/attributes diagrams for a) HGT500; b)T850
Relative operating characteristics (ROC) is another verification measure based on signal detection theory. It is especially useful in ensemble verification because it offers another way of comparing the performance of the control forecasts with that of the ensemble. With this measure, a forecast is better if its hit rate is higher and false alarm rate lower. For each of the 4 ensembles, we check whether a forecast falls into a bin, and a hit rate and a false alarm rate are determined. For the ensemble forecast, the forecast probability of each bin is determined as before and a critical probability y* can be used to interpret the probabilistic forecast to "occur" (the probability is greater than y*) or "not occur" (the probability is less than y*). Clearly, a different hit rate and false alarm rate can be found for each value of y*. 25 different values of y* were used, ranging from 4% to 100% with even intervals of 4%. The ROC for 36 hr are plotted in Figs. 12 a and 12 b with the false alarm rate as the abscissa and the hit rate as the coordinate. Each of the control forecast appears as a single point and the ensemble forecast is represented by a series of points associated with different y*, with the false alarm rate approaching 0 as y* increases. As expected from previous results, the four control forecasts are close to each other, indicating that these forecasting systems have comparable performance. If the critical probability y* is chosen to be 50% or higher, the performance of the ensemble forecast is significantly better to the control forecasts. Note that for the heights the ROC of the FULL ensemble remains above the diagonal line Hit Rate = False Alarm Rate for all critical thresholds, but it crosses it for the temperatures at low critical values. This supports the conclusion that the ensemble forecast for height is more successful than that of temperature since that line (indicated with dots) is the limit for zero skill.
Fig.12 Relative operating characteristic results for the control forecasts and the FULL ensemble forecast. a) HGT500 b) TEMP850Finally, we present in Fig. 13 the correlation between spread and SDE (standard deviation of the error). This is computed by first creating for each grid point (not underground) a pair of values corresponding to the absolute error and to the ensemble spread. For each forecast length the spread and errors of all eight complete cases are lumped together, and the two sets of data are then correlated. This measure can be used the ability of the ensemble to predict the forecast skill a priori (Kalnay and Dalcher, 1987, Palmer and Tibaldi, 1988). For the FULL ensemble, the correlation is quite high, 0.4. This is compares well with other systems, which tend to reach such maximum value later in the forecast (Barker, 1991, Wobus and Kalnay, 1995, Whitaker, 1998). It is very noticeable that among the subsystems the NSSL subsystem starts with very low correlation (due to the use of random initial perturbations) but reaches the highest correlation at 24 hours (due to the use of multiple physical parameterizations).
Fig. 13: Pattern correlation between ensemble spread and forecast error averaged for all complete 8 cases. See text for details.7. Summary and Discussion
The main results of this paper can be summarized as follows:
In summary, the first major conclusion of this study is that an ensemble of multiple systems is close to optimal, probably because it represents most realistically the current uncertainties in the models and in the initial conditions. This result supports previous similar results obtained for the global systems (e.g., Wobus and Kalnay, 1995), which indicated that the average of a small ensemble of 4 operational global models was much better than the best operational system. The second major conclusion is that perturbations in the physics, and BC consistent with perturbations in IC are both important for regional ensemble forecasting.
8. Acknowledgements
We extend our deepest appreciation to all who participated in SAMEX '98. In particular, we acknowledge those who ran their models including Drs. David Stensrud (NSSL), Steve Tracton and Jun Du (NCEP), Randy Lefevre (AFWA), and Jimy Dudhia (NCAR). The entire CAPS team was involved in SAMEX in one way or another, and we give a special thanks to Ming Xue, Fred Carr, Donghai Wang, Henry Neeman, Steve Weygandt, Javon Levit, Yuhe Liu, Vince Wong, Dan Weber, Richard Carpenter, Gene Bassett, Jian Zhang, Yvette Richardson. Jason Levit and Yuhe Liu. In addition, we are very grateful to Y. Zhu for making available climatologically equally probable bins computed from the NCEP/NCAR Reanalysis, and to Drs. Harold Brooks and David Stensrud for several helpful suggestions.
The CAPS and NCEP forecasts were made at the Pittsburgh Supercomputing Center (PSC), and exceptional assistance was provided by Ralph Roskies, Bruce Loftis, and others at the PSC. Drs. Bob Borchers and Richard Hirsh of the National Science Foundation worked tirelessly to ensure our access to PSC, and Jason Martin of the Oklahoma State Regents for Higher Education is gratefully acknowledged for providing high speed access to the internet. This research was supported by the National Science Foundation under Grant ATM91-20009 to the Center for Analysis and Prediction of Storms at the University of Oklahoma.
9. References
Anderson, J.L. 1996: A method for producing and evaluating probabilistic forecasts from ensemble model integrations. J. Climate, 9, 1518-1530.
Benjamin, S. G., J. M. Brown, K. J. Brundage, D. Devenyi, B. Schwartz, T. G. Smirnova, T. L. Smith, and F.-J. Wang, 1996: The 40-km 40-level version of MAPS/RUC. Preprints, 11th Conference on Numerical Weather Prediction, Norfolk.
Black, T. L., 1994: The new NMC mesoscale Eta Model: Description and Forecast Examples. Wea. and Forecasting, 9, 265-278.
Barker, T. W., 1991: The relationship between spread and forecast error in extended range forecasts. J. Climate, 4, 733-742.
Brier, GW, 1950: Verification of forecasts expressed in terms of probabilities. Mon. Wea. Rev.,78, 1-3.
Brooks, H. E., M. S. Tracton, D. J. Stensrud, G. DiMego, and Z. Toth, 1995:
Short range ensemble forecasting: Report from a workshop, 25-27 July 1994, Bull. Amer. Meteor. Soc., 76, 1617-1624.
Brewster, K., 1996: Application of a Bratseth analysis scheme including Doppler radar data. Preprints, 15th Conference on Weather Analysis and Forecasting. Amer. Meteor. Soc., Norfolk, VA, 92-95.
Droegemeier, K.K., 1997a: Outline of plans for SAMEX '98: The 1998 Storm and Mesoscale Ensemble Experiment. Internal Report, Center for Analysis and Prediction of Storms, 4 pp. [Available from CAPS, 100 East Boyd Street, Norman, OK, 73019.]
Droegemeier, K.K., 1997b: The numerical prediction of thunderstorms: Challenges, potential benefits, and results from real-time operational tests. WMO Bulletin, 46, 324-336.
Du, J. and M. S. Tracton, 1999: Impact of lateral boundary conditions on regional-model ensemble prediction. Research Activities in Atmospheric and Oceanic Modelling (edited by H. Ritchie), Report 28, CAS/JSC Working Group Numerical Experimentation (WGNE), WMO/TD-No. 942, 6.7-6.8.
Dudhia, J., 1993: A nonhydrostatic version of the Penn State-NCAR mesoscale
model: Validation tests and simulation of an Atlantic cyclone and cold front.
Mon. Wea. Rev., 121, 1493-1513.
Ebisuzaki, W. and E Kalnay, 1991: Ensemble experiments with a new lagged average forecasting scheme. WMO, Research activities in atmospheric and oceanic modeling. Report #15, pp6.31-6.32. [Available from WMO, C.P. No 2300, CH1211, Geneva, Switzerland].
Grell, G., J. Dudhia, and D. R. Stauffer, 1994: A description of the fifth-
generation Penn State/NCAR Mesoscale Model (MM5). NCAR/TN-398+STR, 121 pp. [Available from MMM Division, NCAR, P. O. Box 3000, Boulder CO 80307].
Hammill, TM and SJ Colucci, 1997: Verification of Eta-RSM short-range ensemble forecasts.
Mon. Wea. Rev., 125, 1322-1327.
Hoffman, R.N. and E. Kalnay, 1983: Lagged Average Forecasting, and Alternative to Monte Carlo Forecasting. Tellus, 35A, 100-118.
Juang, H-M. Henry, Song-You Hong, and Masao Kanamitsu, 1997: The NCEP Regional Spectral Model: An Update. Bull. Amer. Meteor. Soc., 78, 2125-2143.
Kalnay, Eugenia and Amnon Dalcher, 1987: Forecasting forecast skill. Mon. Wea. Rev., 115, 349-356.
Kalnay, E., M. Kanamitsu, R. Kistler, W. Collins, D. Deaven, L. Gandin, M. Iredell, S. Saha, G. White, J. Woollen, Y. Zhu, M. Chelliah, W. Ebisuzaki, W. Higgins, J. Janowiak, K. C. Mo, C. Ropelewski, J. Wang, Leetmaa, R. Reynolds, Roy Jenne, and Dennis Joseph, 1996: The NCEP/NCAR 40-year Reanalysis Project. Bull. Am. Meteor. Soc., 77, 437-471.
Mesinger, F. 1996: Improvements in quantitative precipitation forecasts with the Eta regional model at the National Centers for Environmental Prediction: the 48-km upgrade. Bull.Amer. Meteor. Soc., 77, 2637-2649. Corrigendum: 78, 506.
Molteni, F. and T. N. Palmer, 1993: Predictability and finite time instability of the northern winter circulation. Quart. J. Roy. Met. Soc., 119, 269-298.
Mullen, SL and DP Baumhefner, 1989: The impact of initial condition uncertainty on numerical simulations of large-scale explosive cyclogenesis. Mon. Wea. Rev., 117, 2800-2821.
Palmer, T. N. and S. Tibaldi, 1988: On the prediction of forecast skill. Mon. Wea. Rev., 116, 2453-2480.
Stensrud, D.J., J.-W. Bao, and T.T. Warner, 1999: Using Initial Condition
and Model Physics Perturbations in Short-range Ensembles. Mon. Wea. Rev., in press.
Stensrud, D.J., J.-W. Bao, and T.T. Warner, 1998: Ensemble forecasting of mesoscale convective systems. Preprints, 12th Conf. on Numerical Wea. Prediction, Phoenix, Amer. Meteor. Soc., 265-268.
Takacs, Lawrence, 1985 A two-step scheme for the advection equation with minimized dissipation and dispersion errors. Mon. Wea. Rev., 113, 1050-1065.
Toth, Z. and E. Kalnay, 1993: Ensemble forecasting at NMC: the generation of perturbations. Bull. Amer. Meteor. Soc., 74, 2317-2330.
Toth, Zoltan and Eugenia Kalnay, 1997: Ensemble Forecasting at NCEP: the breeding method. Mon. Wea. Rev.,125, 3297-3318
Toth, Zoltan, Eugenia Kalnay, Steve Tracton, Richard Wobus, and Joseph Irwin, 1997: A synoptic evaluation of the NCEP ensemble. Wea. and Forecasting, 12, 140-153.
Tracton, S., J. Du, Z. Toth, and H Juang, 1998: Short-range ensemble forecasting (SREF) at NCEP/EMC. Preprints, 12th Conf. on Numerical Weather Prediction. Phoenix, AZ, Amer. Meteor. Soc., 269-272.
Wilks, DS, 1995: Statistical methods in the atmospheric sciences. Academic Press, New York, 467pp.
Wobus, R. and E. Kalnay, 1995: Three years of operational prediction of forecast skill,. Mon. Wea. Rev., 123, 2132-2148.
Xue, M., K.K. Droegemeier, V. Wong, A. Shapiro, and K. Brewster, 1995: ARPS Version 4.0 User’s Guide, 380pp. [Available from the Center for Analysis and Prediction of Storms, 100 East Boyd Street, Norman, OK, 73019.]
Zhu, Y, G. Iyengar, Z Toth, MS Tracton and T Marchok, 1996: Objective evaluation of the NCEP global ensemble forecasting system. Preprints, 15th Conference on Weather Analysis and Forecasting. Norfolk, VA, Amer. Meteor. Soc., J79-J82.
List of Figures
Fig. 1 The common domain used for forecast display and verification.Fig. 2 Time series of the ensemble spread for mean sea level pressure (MSLP), 250hPa heights (HGT250), 500 hPa heights (HGT500), and 850hPa heights (HGT850), averaged over the 8 cases with complete data sets.
Fig. 3 Same as in Fig. 2 but for temperature at 850 hPa (TEMP850), the 2m surface air and dew point temperature (TEMP2M and DEWP2M) and 3hr accumulated precipitation (ACCPPT).
Fig. 4 Time series of average error statistics for 500 hPa for individual ensembles and the FULL and CONTROL ensembles. a) Mean bias error MNBIAS, b) Bias of the standard deviation, c) dispersion (DISP) error, and d) forecast/analysis correlations. The average score of the individual ensemble members are also indicated with different symbols.
Fig. 5: Same as in Fig.4 except for TMP850. Fig. 6: Time series of SD of errors (SDE) of HGT500 (upper panel) and TMP850 (lower panel), for CAPS ensemble, averaged over the 8 cases of complete data sets.Fig. 7: Relative frequencies at which the verifying analysis falls in each of the 26 categories, defined by the 25 ordered ensemble members at each grid points, for the FULL ensemble HGT500 forecast. a) 12hr forecasts; b) 24hr forecasts; c) 36 hr forecasts.
Fig. 8: Same as in Fig 7 except for TEMP850.
Fig. 9: Frequencies at which the ensemble does not encompass the verifying analysis, adjusted according to the size of the ensembles (see the text for detail). Fig. 10: a) Bins of equal probabilistic distribution of the climatological 500 hPa heights during May at a point in the center of the SAMEX domain. B) Same as a) but for 850 hPa temperatures. Fig.11: 24 hour forecast reliability/attributes diagrams for a) HGT500; b)T850 Fig.12: Relative operating characteristic results for the control forecasts and the FULL ensemble forecast. a) HGT500 b) TEMP850 Fig. 13: Pattern correlation between ensemble spread and forecast error averaged for all complete 8 cases. See text for details.